Вступление
Когда приходится реализовывать реальные проекты с использованием моделей для машинного обучения-разработчик часто сталкивается с большим количеством проблем:
-
Как получать данные?
-
Как их обрабатывать?
-
Как подавать на инференс?
-
Как подружить между собой модели из ансабля?
-
Как адекватно получить результат для дальнейшего использования?
Сегодня я расскажу о MindX SDK-инструменте, который позволяет решить эти проблемы быстро и просто.
Но, для начала необходимо немного рассказать про платформу, на которой мы и будем работать.
Atlas-это ИИ платформа, включающая в себя набор продуктов и решений, работающих на NPU (Neural processing Unit) Ascend.

Ascend – это чип, разработанный на основе архитектуры Da Vinci.
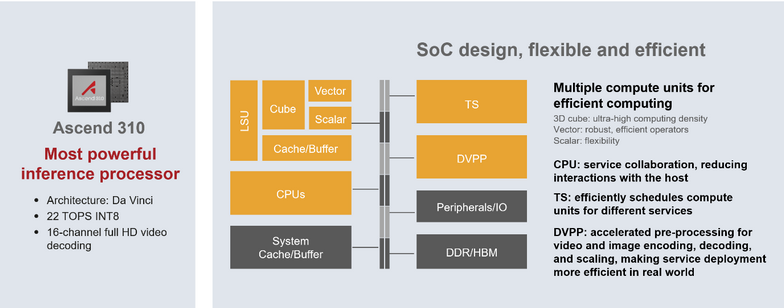
Его особенностью является наличие отдельных сопроцессоров для различных операций. Например,
Cube-кубический сопроцессор. Используется для перемножения матриц
Vector-используется для исполнения операций над векторами
DVPP-сопроцессор для нативной обработки изображений и видео.
Все эти операции выполняются на аппаратном уровне с помощью Minx DL. Mindx DL-это программная архитектура устройств Huawei для работы с машинным обучением.
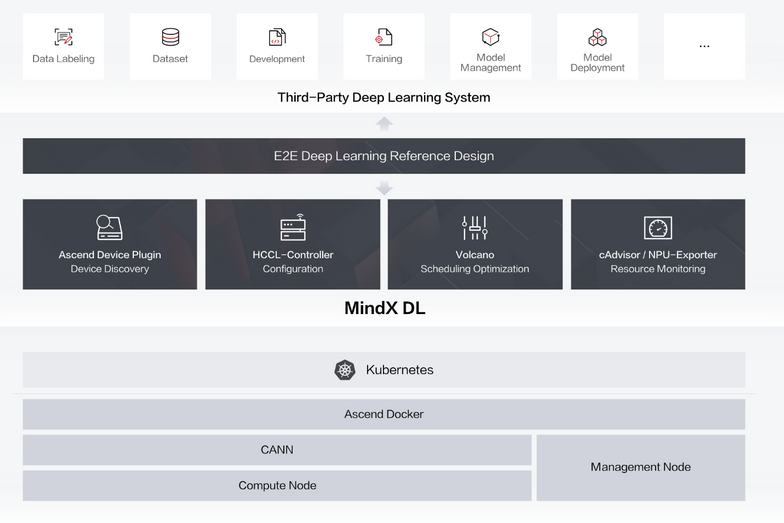
Теперь, после того как вы получили представление о том, на чем мы будем работать, давайте перейдем к примерам.
Пример 1
MindX SDK позволяет строить пайплайны машинного обучения в виде JSON из готовых плагинов. После чего вызывать пайплайн из кода и работать с ним дальше. Теперь, давайте рассмотри конкретный пример.
Допустим, вам необходимо определить объект на .jpg изображении с помощью YOLOv3 и вывести результаты в командную строку.
Для начала, рассмотрим наш пайплайн.
{
"classification+detection": {
"stream_config": {
"deviceId": "0"
},
"mxpi_imagedecoder0": {
"factory": "mxpi_imagedecoder",
"next": "mxpi_imageresize0"
},
"mxpi_imageresize0": {
"factory": "mxpi_imageresize",
"next": "mxpi_modelinfer0"
},
"mxpi_modelinfer0": {
"props": {
"modelPath": "../models/yolov3/yolov3_tf_bs1_fp16.om",
"postProcessConfigPath": "../models/yolov3/yolov3_tf_bs1_fp16.cfg",
"labelPath": "../models/yolov3/coco.names",
"postProcessLibPath": "libMpYOLOv3PostProcessor.so"
},
"factory": "mxpi_modelinfer",
"next": " mxpi_dataserialize0"
},
"mxpi_dataserialize0": {
"props": {
"outputDataKeys": "mxpi_modelinfer0 "
},
"factory": "mxpi_dataserialize",
"next": "appsink0"
},
"appsrc0": {
"props": {
"blocksize": "409600"
},
"factory": "appsrc",
"next": "mxpi_imagedecoder0"
},
"appsink0": {
"props": {
"blocksize": "4096000"
},
"factory": "appsink"
}
}
}
Пайплайн представляет собой JSON файл с разрешением .pipeline
Каждый элемент этого пайплайна-это отдельный плагин, реализующий типичную функцию. Мы выстраиваем их в нужном нам порядке. Давайте посмотрим на них поближе:
"classification+detection": {
"stream_config": {
"deviceId": "0"
},
Первый элемент пайплайна, в котором мы определяем его имя и ID устройства на котором он будет исполняться. ID устройства-ID чипа Ascend, на котором мы хотим исполнить наш пайплайн.
"appsrc0": {
"props": {
"blocksize": "409600"
},
"factory": "appsrc",
"next": "mxpi_imagedecoder0"
},
Элемент, отвечающий за подачу данных. Именно считывает нашу картинку. Здесь можно поговорить об устройстве плагина. Каждый плагин строится на основании существующей фабрики-нам нужно лишь указать его параметры.
"mxpi_imagedecoder0": {
"factory": "mxpi_imagedecoder",
"next": "mxpi_imageresize0"
},
Декодер изображений. Именно он отвечает за преобработку изображений для выполнения операций на NPU. Декодирование происходит на аппаратном уровне, при помощи DVPP.
Здесь можно заметить, что у каждого плагина есть свой предок и свой потомок, при этом, непосредственно в коде, мы можем выстраивать их как нам угодно: главное указать правильного потомка.
"mxpi_imageresize0": {
"factory": "mxpi_imageresize",
"next": "mxpi_modelinfer0"
},
Плагин, отвечающий за изменение размерности поданного на вход ихображения. По дефолту подстраивается под нашу модель, но в некоторых случаях можно указать конкретный размер. Ресайз также происходит на DVPP.
"mxpi_modelinfer0": {
"props": {
"modelPath": "../models/yolov3/yolov3_tf_bs1_fp16.om",
"postProcessConfigPath": "../models/yolov3/yolov3_tf_bs1_fp16.cfg",
"labelPath": "../models/yolov3/coco.names",
"postProcessLibPath": "libMpYOLOv3PostProcessor.so"
},
"factory": "mxpi_modelinfer",
"next": " mxpi_dataserialize0"
},
Здесь начинается самое интересное. Плагин modelinfer отвечает непосредственно за инференс нашей модели. На нем я остановлюсь поподробнее.
Вы можете видеть четыре параметра:
modelPath-параметр отвечающий за расположение модели, относительно директории, откуда запускается код
postProcessConfigPath-путь к конфигу постпроцессинга
labelpath-путь к файлу, содержащему леблы нашиз классов
postProcessLibPath-путь к библиотеке постпроцессинга. Каждой модели соответсвует своя библиотека поспроцессинга. Это просто скомпилированный алгоритм на c++, отвечающий за корректный вывод информации. По умолчанию в пакет MindxSDK включены библиотеки для обработки абсолютного большинства актуальных моделей.
"mxpi_dataserialize0": {
"props": {
"outputDataKeys": "mxpi_modelinfer0,mxpi_modelinfer1"
},
"factory": "mxpi_dataserialize",
"next": "appsink0"
},
Сериализация данных. Нужна для формирования JSON на выходе.
"appsink0": {
"props": {
"blocksize": "4096000"
},
"factory": "appsink"
}
Финальный плагин, выводящий данные.
Вот и все! Теперь давайте разберемся как работать в коде с нашим пайплайном.
Для найчала импортируем наш API, после чего инциируем его:
from StreamManagerApi import *
if __name__ == '__main__':
streamManagerApi = StreamManagerApi()
ret = streamManagerApi.InitManager()
if ret != 0:
print("Failed to init Stream manager, ret=%s" % str(ret))
exit()
После, создаем стрим на основе нашего пайплайна:
with open("../pipeline/Sample.pipeline", 'rb') as f:
pipelineStr = f.read()
ret = streamManagerApi.CreateMultipleStreams(pipelineStr)
if ret != 0:
print("Failed to create Stream, ret=%s" % str(ret))
exit()
Считываем наш файл:
dataInput = MxDataInput()
with open("test.jpg", 'rb') as f:
dataInput.data = f.read()
Подаем данные на вход пайплайну:
streamName = b'classification+detection'
inPluginId = 0
uniqueId = streamManagerApi.SendDataWithUniqueId(streamName, inPluginId, dataInput)
if uniqueId < 0:
print("Failed to send data to stream.")
exit()
Получаем результат:
inferResult = streamManagerApi.GetResultWithUniqueId(streamName, uniqueId, 3000)
if inferResult.errorCode != 0:
print("GetResultWithUniqueId error. errorCode=%d, errorMsg=%s" % (
inferResult.errorCode, inferResult.data.decode()))
exit()
И выводим его в командную строку:
print(inferResult.data.decode())
На входе у нас была вот такая милая собачка:

На выходе же получили:
[{"classId":16,"className":"dog","confidence":0.99774956699999995,"headerVec":[]}],"x0":148.74237099999999,"x1":886.13958700000001,
"y0":138.61973599999999,"y1":607.11614999999995}]
Теперь давайте разберем менее тривиальный кейс. А конкретно-мы будем получать данные из RTSP потока и обрабатывать в реальном времени, после чего отображать их в окне. Для теста я использую YOLOv3 и стримлю видео локально с помощью live555MediaServer.
Для начала, вот наш пайплайн:
{
"detection": {
"stream_config": {
"deviceId": "0"
},
"mxpi_rtspsrc0": {
"factory": "mxpi_rtspsrc",
"props": {
"rtspUrl": "rtsp://183.16.4.12/output.mkv",
"channelId": "0"
},
"next": "mxpi_videodecoder0"
},
"mxpi_videodecoder0": {
"factory": "mxpi_videodecoder",
"props": {
"inputVideoFormat": "H264",
"outputImageFormat": "YUV420SP_NV12",
"vdecChannelId": "0"
},
"former": "mxpi_rtspsrc0",
"next": "mxpi_imageresize0"
},
"mxpi_imageresize0": {
"props": {
"dataSource": "mxpi_videodecoder0",
"resizeHeight": "416",
"resizeWidth": "416",
"resizeType": "Resizer_KeepAspectRatio_Fit"
},
"factory": "mxpi_imageresize",
"next": "mxpi_modelinfer0"
},
"mxpi_modelinfer0":{
"next":"appsink0",
"factory":"mxpi_modelinfer",
"props":{
"postProcessLibPath":"../../../lib/libMpYOLOv3PostProcessor.so",
"modelPath":"../models/yolov3/yolov3_tf_bs1_fp16.om",
"dataSource":"mxpi_imageresize0",
"labelPath":"../models/yolov3/coco.names",
"postProcessConfigPath":"../models/yolov3/yolov3_tf_bs1_fp16.cfg"
}
},
"appsink0": {
"factory": "appsink"
}
}
}
Из нового- здесь плагины mxpi_rtspsrc, где мы указываем адрес нашего стрима и mxpi_videodecoder, который отвечает за обработку видео на сопроцессоре DVPP.
Теперь о том, как работать в коде с этим пайплайном. Для рисования рамок и отображения в окне я буду использовать OpenCV.
Работа со стримом практически ничем не отличается от работы с картинкой, кроме того, что нам нужно получать не только результат, но и рисовать рамки на изображении. Для этого, чы должны получать данные самого изображения.
key1 = b'mxpi_videodecoder0' key2 = b'mxpi_modelinfer0' key_vec = StringVector() key_vec.push_back(key1) key_vec.push_back(key2) infer_result = streamManagerApi.GetResult(b'detection', b'appsink0', key_vec, 3000)
Поэтому, мы берем данные сразу с двух плагинов.
По дефолту, изображения обрабатываются в YUV. C Помощью встроенной функции OpenCV мы переводим YUV в BGR.
frame = np.frombuffer(dataStr, dtype=np.uint8) height = visionInfo.height width = visionInfo.width shape = (int(height*1.5),width) frame_yuv = frame.reshape(shape) frame_bgr = cv2.cvtColor(frame_yuv,cv2.COLOR_YUV2RGB_NV21)
После чего рисуем наши боксы:
out_frame = draw_img_fun(frame_bgr, str(frame_index), bbox, confidence, classname)
Складываем наши изображения и выводим на экран:
vis = np.concatenate((frame_bgr, out_frame), axis=1)
cv2.imshow("video",vis)
Результат:
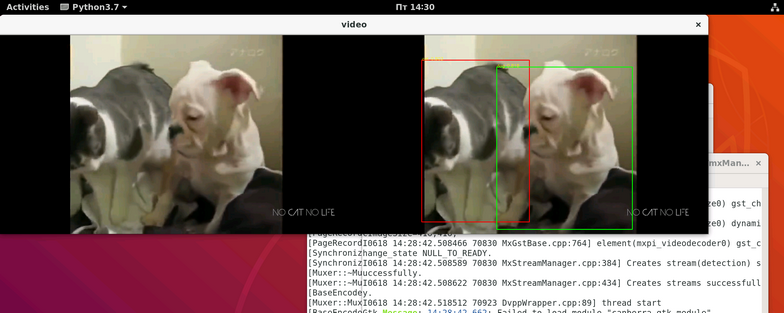
Вот и все. Как вы можете заметить, писать пайпланы с помощью готовых плагинов – это быстро просто и удобно.